Wētā FX has developed an entirely new face pipeline. The team first developed this breakthrough new approach in 2019, but the company has only just revealed the new approach at SIGGRAPH ASIA in Korea, to coincide with the release of Avatar: The Way of Water. In this in-depth discussion, we talk directly with Wētā FX Snr. VFX Supervisor Joe Letteri about why he made the decision to develop the new approach and with Karan Singh one of the other authors on the technical paper.

Background
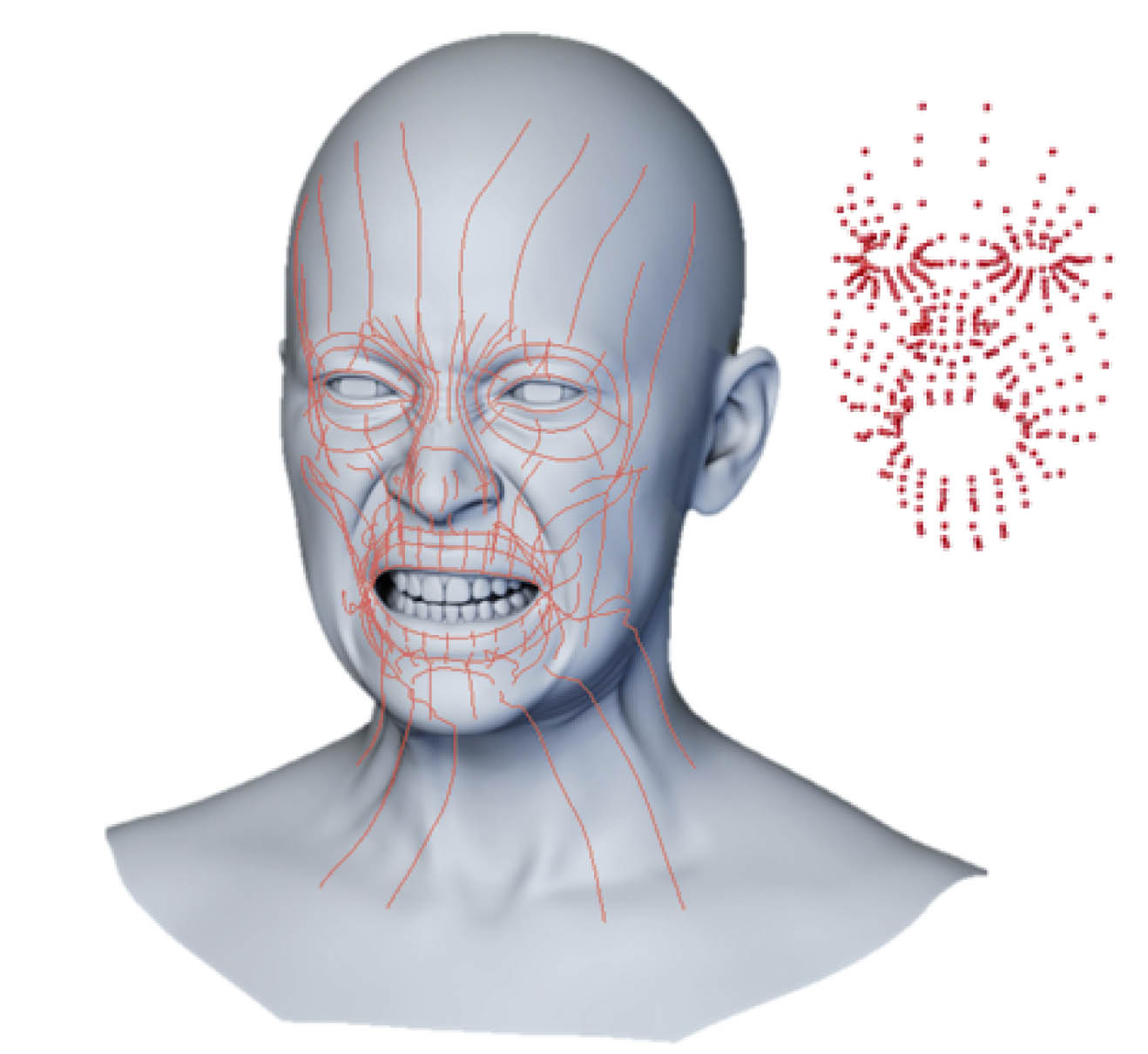
The new system of facial animation is based on moving from a FACS puppet to muscle fiber curves as an anatomic base. The new approach is called the Anatomically Plausible Facial System or APFS and it is an animator-centric, anatomically inspired system for facial modeling, animation, and re-targeting transfer.

The new system replaces the award-winning FACS pipeline that Wētā FX has used consistently since Gollum. Having pushed the R&D FACS approach extremely hard for the film Alita: Battle Angel (2019), Letteri decided that a FACS-based puppet system just had too many major issues such as face muscle separation, coverage, linear combinatorial use, and wide-scale redundancy. For example, while FACS maps a set of facial poses that denote muscle-driven expressions, to get adequate facial animation a FACS puppet rig may end up with as many as 900 FACS shapes being added to a rig to allow an animator to achieve a believable performance. It is not that FACS is ‘wrong’, it is just not a system that was designed for time-based facial animation. It was not built around speech but rather isolated emotional expressions. “We needed a system that allowed artists direct control of how a face behaves,” comments Letteri. “A FACS system only emulates a face from the outside and has very limited capabilities… it is only an emotion-based system, it codes expressions. There is no dialogue encoded in FACS, and mostly what we do is dialogue.” While FACS may represent an accurate isolated expression, there is no information on how to transition between poses, “You end up having to sort of guess, … it’s like you’re intuiting the transition, which is great, but it’s hard to maintain,” Letteri explains. “It’s also very kind of ‘rubbery’, A FACS system can be very rubbery because you have these state changes happening basically linearly all over the face as you move from state to state.
Letteri and his team decided to start over and approach the whole face pipeline from scratch. “I started looking at the problem and thinking: I don’t wanna do this anymore. This is too hard. There’s, there’s gotta be a better way.” he recalls. “I started going back and just looking at the muscles in the face and how they’re laid out and how they’re all connected. I realized that if you map out those connections you have the basis for a high-dimensional space that could describe the face,”
The team focused on the fact that an expression is made, and a muscle is activated that other muscles are activating in tandem or that muscles are being pulled passively.”Because of the way the muscles are interconnected, in a kind of network that closely resembles a neural network,” Letteri reasoned. “Then I thought, why don’t we just make a neural network that uses the muscles directly as the basis? In other words, a lot of deep learning tries to throw numbers at a problem, give it a lot of data and it will try to figure out correlations for you. And I thought, no, we actually already know the correlations, so why don’t we just code that as our basis? If you get into the math of it, then it’s a big derivative chain. It is basic calculus”. The team then aimed to bring together a system that gives an animator a unique way of representing any combination of jaw, eyes, and muscles, “As a basis, it’s fantastic because we can now train the system to look at say Sigourney Weaver’s face and try to solve for what the ‘muscles’ are doing, and then run another network that will transfer that to the character.” In addition, with the muscle curves, the animators now have direct control, muscle-by-muscle of the face. It is important to point out however that the muscle curves are not one-for-one designed to match actual muscles under the skin. The muscle curves are designed to solve the face but in a way that animators can control and yet that matches facial movements that are performance captured at an incredibly high level of fidelity.
APFS
The new APFS is based on 178 muscle fiber curves or ‘strain’ curves. These curves can contract or relax to provide fine-grained high-fidelity human facial expressions. The end-to-end systems is both inward-out (the face is driven by the muscle fiber curves) and outside-in, (an animator can ‘correctly’ drag and move the face from the surface of the face). The system is not a 1:1 mapping of human muscles as some facial aspects such as top lip curvature is actually a result driven by jaw and lower facial muscles. Rather, the system is a spanning array of 178 curves that allow for an anatomically inspired set of controls, but not a direct flesh/muscle emulation and simulation. Furthermore, FACS puppets are built on a linear combination of FACS expressions that do not encompass rotation. To get correct eyelid animation which naturally involves a rotational component around the eyeball, a set of intermediate FACS shapes need to be added.
Eyelid example
Each muscle or strain curve has an associated strain value. Muscle curves don’t really twist but the strain value provides a contraction or expansion along the curve, in its local space. In a sense, it is a percentage length change. The actual curve strain number is unitless and this aids in transferring to different characters. The strain values don’t so much work in isolation as much as they do as part of a set. For example, for an eyelid blink there are both muscle curves along the line of the eyelash (horizontally) and also orthogonally (vertically, up and down, around the eye). In this case, the horizontal curve does not change much in actual strain value, since it is rotating over the eyeball, while the vertical curves are dramatically changing in strain value. But most importantly as the vertical curve scales along the curve shape of the muscle curve – which matches the curve of the eyeball. A similar blendshape transition between an open and closed blendshape, would just move in a straight line from close to open (without bending around the eyeball). In Maya, you can chain blendshapes to simulate the eyelid curving around the eyeball, but again this adds to the bloated blendshape count.
While FACS solutions have allowed a level of standardization across facial rigs, FACS was designed from a psychological standpoint to capture voluntary, distinguishable snapshots of facial expression, and has clear limitations when applied to computer animation. FACS Action Units (AUs) need to be combined with subtraction to achieve the desired expression as the AUs that combine the action of multiple facial muscles or do not involve facial muscles at all), localization and animation control (AUs that can be redundant, opposing in action, strongly co-related, or mutually exclusive), and AUs only approximate the complex shape deformations of a hinged jaw and human lips. Machine learning was used to build the new system. 6000-8000 scans (frames) from 80 dynamic motion clips were used. About 60% are FACS shape poses and 40% are speech motions. Each actor’s performance was solved based on 340 markers from validated ground-truth expressions. The APFS pipeline does not encode any temporal information, this comes from the performance capture solve itself. The animation inherently tracks the motion and expressions of the actor.

The Jaw
Jaws and lips get extra attention in the new system, “because one of the other things that I noticed when we were building the system is the primary control for the state of your face is the jaw,” Letteri recounts. “Especially with dialogue, your jaw’s constantly moving. It is the main driver of state” Additionally as the jaw of any person can only move in the locus shape of a shield. The mandible, or lower jawbone, is attached to the skull via the temporomandibular joint and held in place by ligaments and muscles. As such the range of motion of the jaw can be mapped by tracing a set of notional points on the jaw. When you map a set of such points over all possible dialogue and expressions of a person, you get the shape of a shield. This is known as Posselt’s Envelope of Motion or the Posselt shield. “The shield is built into a constraint system, for the driver itself,” Letteri explains. “The muscles get solved on top of that.” This is because when the team is solving for any actor, they do a forensic fit of a digital skull to the actor. They then figure out the range of motion of the jaw, then do a solve using the HMC stereo cameras to extract depth information. “Then we run a PCA on that to try to get the best fit so that we have a coherent mesh. Then the jaw and the skull get fit to that,” he adds. If the team is performance-capturing then the motion and range of movement are already accounted for in the human action. But if they are animating it by hand, then their Jaw controller has shield constraints built into it. The animation was verified by observing teeth alignment against images captured from each camera for that actor.
Similarly, the actor’s eyes are very carefully handled. The system’s eye model matches the actor’s sclera, cornea, and iris. Eye gaze direction is adjusted in each frame by rotating the eyeballs so that the iris model aligns with the limbal ring and pupil, visible on the images captured from each camera. Eyes are very hard to track, due to the lensing of the eye and the refraction it displays. Multiple camera angles are used to verify the alignment and account for light refracted by the cornea. Even a small frontal eye bulge is applied to each eye rotation to enhance the character’s eye realism.

Tetrahedrals (Tet) Facial Volumes
As the curve muscle are just lines, there needs to be a link between the strain muscles and the skin of the digital character. The curves are capturing the lines of muscle action, but they are also embedded inside the actual face. Here the face is simulated by a volumetric representation using a tetrahedral volume discretizing the soft tissue of the face in the character’s rest pose. The tet volume solution sits between the skin and the bones of the skull and jaw. The tets form a conceptual or mathematical ‘jello’. A passive, quasi-static simulation is performed on this tet volume for whole scan sequences with skin vertices and the skull as positional constraints. Using finite element analysis (FEA), a ‘passive simulation’ of the 135,000 tets (constrained with multiple positional, sliding, and collision constraints) is performed in a frame-to-frame way, and this produces anatomically plausible flesh behavior. The ‘flesh mask’ that is generated here only has a role in the training stage.

Actual Muscle Ribbons vs Muscle Curves
While the muscles of the face are often ribbon-muscles, the APFS curves have no width. Additional curves have been added where needed to account for this. The muscle curves are not active muscle sims, “and in fact, the animators don’t want that,” comments Karan Singh, Professor of Computer Science at the University of Toronto who worked on the project. “They (the animators) want frame-to-frame control. They want kinematic deformation control. They really don’t want to have to set up a (sim) configuration and then hit playback to see an actual active simulation take over.” For that reason, he believes the team chose the curve representation and “decided to just stick with the curves,” he adds. “We took the minimum, the absolute minimum kind of parametric representation that we could.”

Karan Singh, joined the team in 2020, just before COVID, as he was in New Zealand as a visiting researcher. While he would be the first to say he was not the lead researcher, he played a major role in getting the process written up for the SIGGRAPH ASIA Submission and was in Korea for the presentation with Byungkuk Choi Haekwang Eom and Benjamin Mouscadet who did the live presentation. Each of the engineers had a particular focus and module as part of the large end-to-end solution. The paper actually has 12 authors including Joe Letteri and Karan Singh.
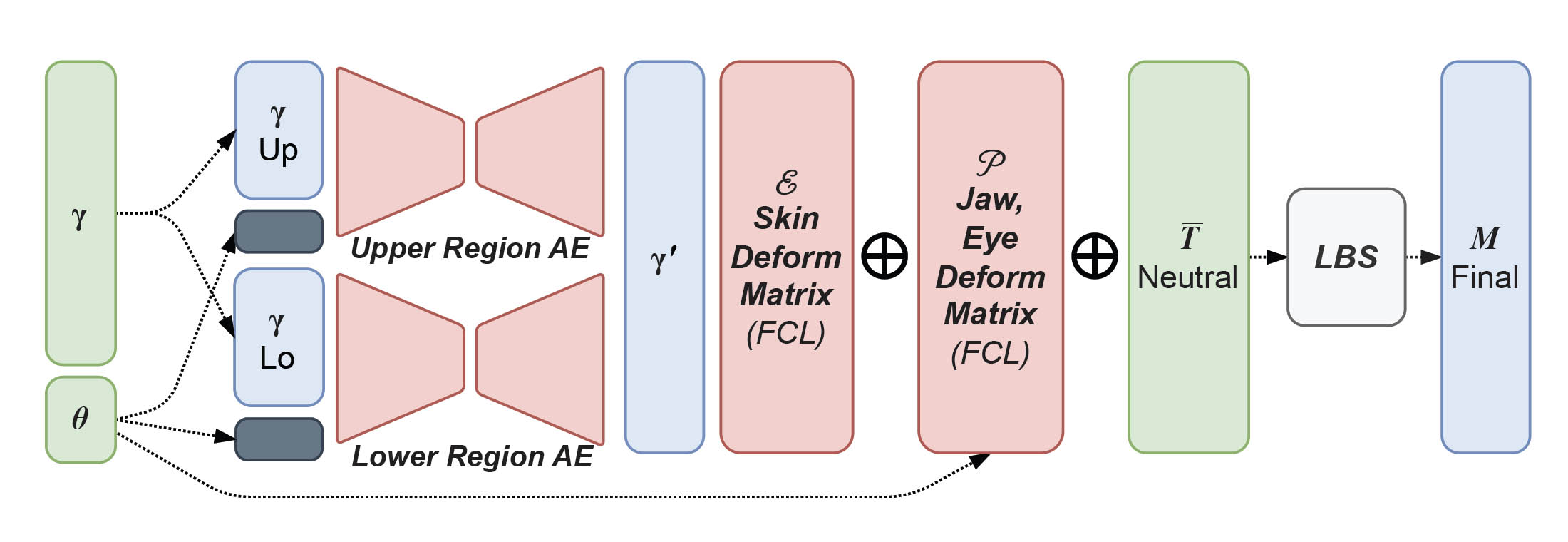
Singh wrote the actual original blendshape code in Autodesk’s Maya earlier in his career, so he is very familiar with the detailed code used around FACS puppets. Singh points to the clever use of Machine Learning (ML) Autoencoders (AE), inside the new pipeline, to keep the expressions on-model. ML is transforming pipelines such as Wētā’s but not in ways that many people fully yet understand. Much is written about VAE and their use as deepfake face-swapping tools, but the APFS team demonstrates here how ML tools such as AEs are being used inside complex pipelines to assist in key tasks, while not being explicitly used for final pixels.
The system can go off model easily using traditional FACS blendshapes, but the solution space is bounded by the AEs. “When you define through early tests and training data for individual characters, you are setting the range of that character,” Singh explains. “The autoencoder sort of encodes that, – so it’s not just a generic setting that you are encoding. You are actually encoding a very specific set of performances.” The AE in the way that the pipeline is constructed really keeps the face on target and on-model.
Transfer Pose Libraries
Animators naturally are used to having pose libraries. And there is nothing wrong with a pose library, but poses do not enforce or encode any motion and combinatorial use can easily go off model. To better provide a familiar working environment a strain-based motion library was built for the animators. This outside-in approach provides an Inverse mapping to the curves. But given how the system is built and the use of an autoencoder, the animator cannot accidentally go off-model. Muscle stretching and contracting might be intuitive but driving a facial expression with the strain vector is not straightforward. The team incorporated an autoencoder (AE) to assist artists by constraining the strain vectors to remain within the boundaries of plausible face animation. The on-model solution space is called the expression manifold. It is up to the animator to define what is plausible here, and an animator can choose to go off-model deliberately, but the expression manifold is estimated for them using a curated sampling of multiple facial expressions and the corresponding range of strain vectors or settings.

Deep Shape
In Avatar: The Way of Water many of the actors were performance captured in water, but most of their facial animation was based on a secondary capture on dry land which was then blended with the main performance capture. When giving facial performance captures the actors wore a stereo head rig (HMC), which thanks to newer technology were no heavier than the original HMCs from Avatar 1.
Thanks to the fixed stereo arrangement of the HMC cameras, the team at Wētā developed a powerful new visualization tool called Deep Shape. The stereo images are used to provide a 3D point cloud-style reconstruction of the actor’s actual performance that can be viewed from any angle. The image is monochrome and not polygonized but highly representative of the actual performance. This new visualization allows an animator to have a virtualized witness camera as if filmed only a few feet from the face, without the wide-angle distortion and odd viewing angle of the raw output of either of the actual capture cameras. Such a 3D depth-reconstructed view allows for a much more powerful way to view lip and jaw extensions and judge if later fully controllable and reconstructed animation is faithful to the raw view. It is such a remarkably useful viewing device it is surprising no one has implemented this before, but to our knowledge, Wētā FX is the first team to accurately achieve the Deep Shape visualization option. This tool provides a key reference tool of the facial ground truth to compare and judge the APFSemulation. It is yet another innovation in the new end-toe-end APFS based solution.

Aging
As is now common practice, the team animated the actor’s digital double that matches the facial expressions with very high fidelity and then transfer the animation to the character model. To maximize the match between an actor and their character’s face in animation transfer, Wētā strategically design their character training process to share the corresponding actor’s underlying muscle behavior. The 3D character facial model ends up having the same shared strain autoencoder, identical to their respective actor. The skin is mapped exactly and the eye and jaw regions are handled separately, using user-defined weight maps, to allow for more accurate expression transfers of those key facial parts. Naturally given the Na’vi’s unique form, the team needs to carefully fit the actor’s jaw rig to the character and use it to compensate for the deviation in teeth topography and skull anatomy.

The curve muscle system has a set of curves extending down into the neck region to allow for better integration with body performance capture. There are completely separate controls for the ears, “the reason we didn’t bother to try to capture them, in this particular case, is that they are a kind of secondary effect,” says Letteri. “The ears don’t actually drive anything themselves, and with the Na’vi, they have expressive ears that are not obviously represented at all in humans. So that’s just a separate animation control system.”

In the film, there is naturally a host of re-targeting to the Na’vi, but importantly there are also two key de-aging retargets. Both actors Sigourney Weaver and Stephen Lang are retargeted to younger characters: Kiri and a younger Quaritch. While one might explore varying the strain values to simulate the loosening and aging of facial muscles, Letteri points out that the retargeting fully compensated for that and the strain values did not need to be ‘eased’ or stretched. “We thought about doing that, but it would add a level of uncertainty,” comments Letteri. “So we thought, let’s just try it in the retargeting first because if it works, it’s a much simpler solution. And that’s what we did. And we got that to work well for us.”

Photos courtesy of 20th Century Studios. © 2022 20th Century Studios. All Rights Reserved.
The original Animatomy: an Animator-centric, Anatomically Inspired System for 3D Facial Modeling, Animation and Transfer SIGGRAPH ASIA paper was written by Byungkuk Choi, Haekwang Eom, Benjamin Mouscadet, Stephen Cullingford, Kurt Ma, Stefanie Gassel, Suzi Kim, Andrew Moffat, Millicent Maier, Marco Revelant, Joe Letteri and Karan Singh.